## The following code loads the libraries needed for the analysis:library(dplyr)library(ExPosition)library(knitr)library(kableExtra)library(ggplot2)library(InPosition)library(R4SPISE2022)## Ensures reproducibility of bootstrap and permutationsset.seed(564)## Load the Wine datadata("winesOf3Colors", package ="data4PCCAR")wines <- winesOf3Colors$winesDescriptors[,4:17]## Define colors...### of the wines...wineColors <-list(oc =cbind(as.character(recode( winesOf3Colors$winesDescriptors$color,red ='indianred4', white ='gold',rose ='lightpink2'))),gc =cbind(c(red ='indianred4', white ='gold', rose ='lightpink2')))### ... and of the variablesvarColors <-list(oc =list(cbind(rep("darkorange1", 4)),cbind(rep("olivedrab3", 8)) ))## Run the Principal Component Analysis (PCA)res.pca <-epPCA(wines, center =TRUE, # Center the datascale =TRUE, # Normalize the variablesgraphs =FALSE) # By default, this function will preprocess the variables in the data set (i.e., the columns of the data table) by 1) centering them (`option center = TRUE` after pre-processing all variables have mean equals to 0) and 2) scaling them (`option scale = TRUE` after pre-processing all variables have a sum of squares equals to \eqn{N - 1}, \eqn{N} being the number of rows).## Generate the plotsres.plot.pca <-OTAplot(resPCA = res.pca,data = wines, col4I = wineColors$oc )## What's in the results:# - `results.stats`: useful statistics after performing PCA, among which one can find the factor scores, loadings, eigenvalues, and contributions;# - `results.graphs`: all the PCA graphs (heatmaps, screeplot, factor map, correlation circles, loading maps etc.)# - `description.graphs`: the titles of these graphs, used as titles in the PPTX file.
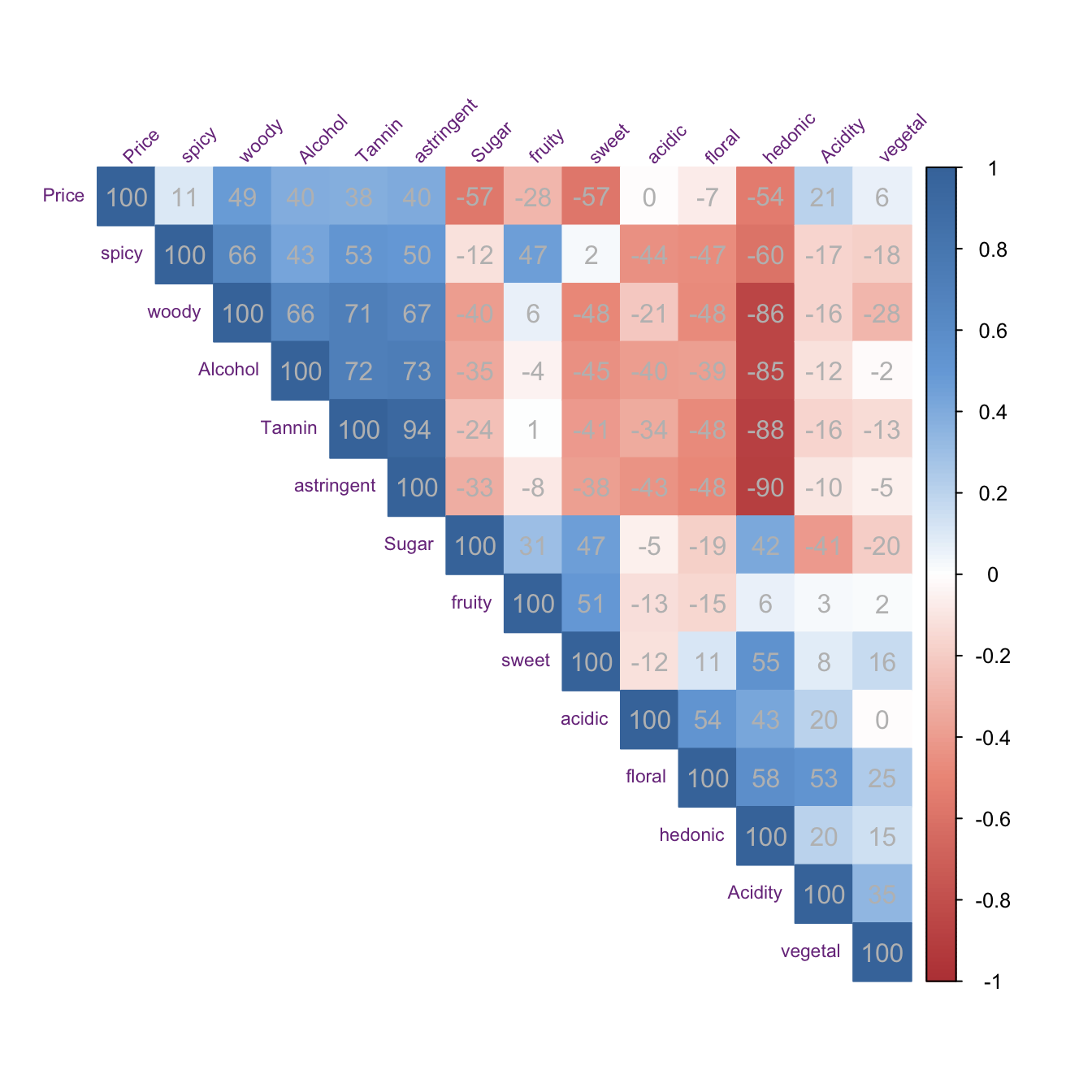
Correlations of the variables
We can check the data by plotting the correlation matrix between the variables. This correlation matrix is where the components are extracted.
R code
res.plot.pca$results.graphs$correlation
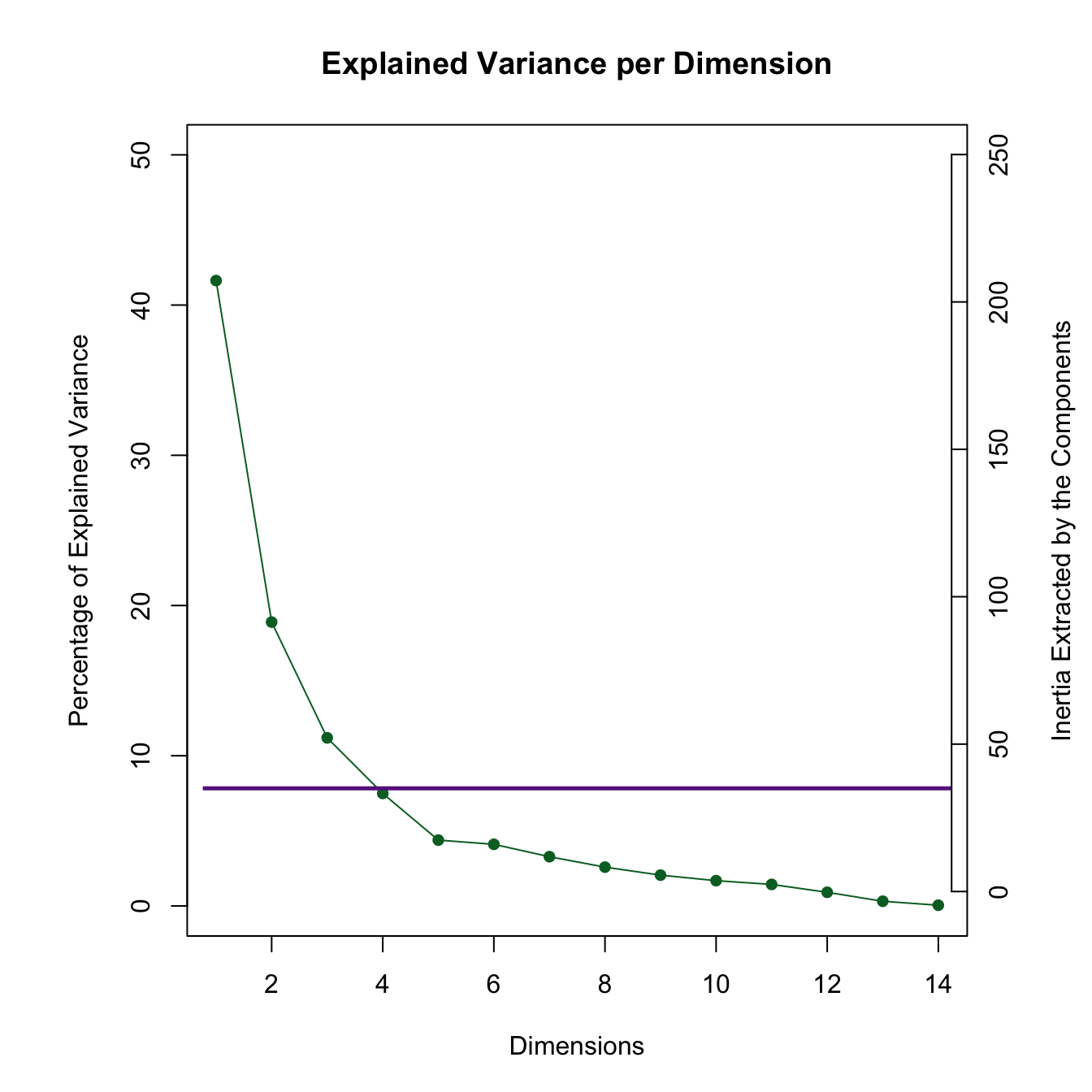
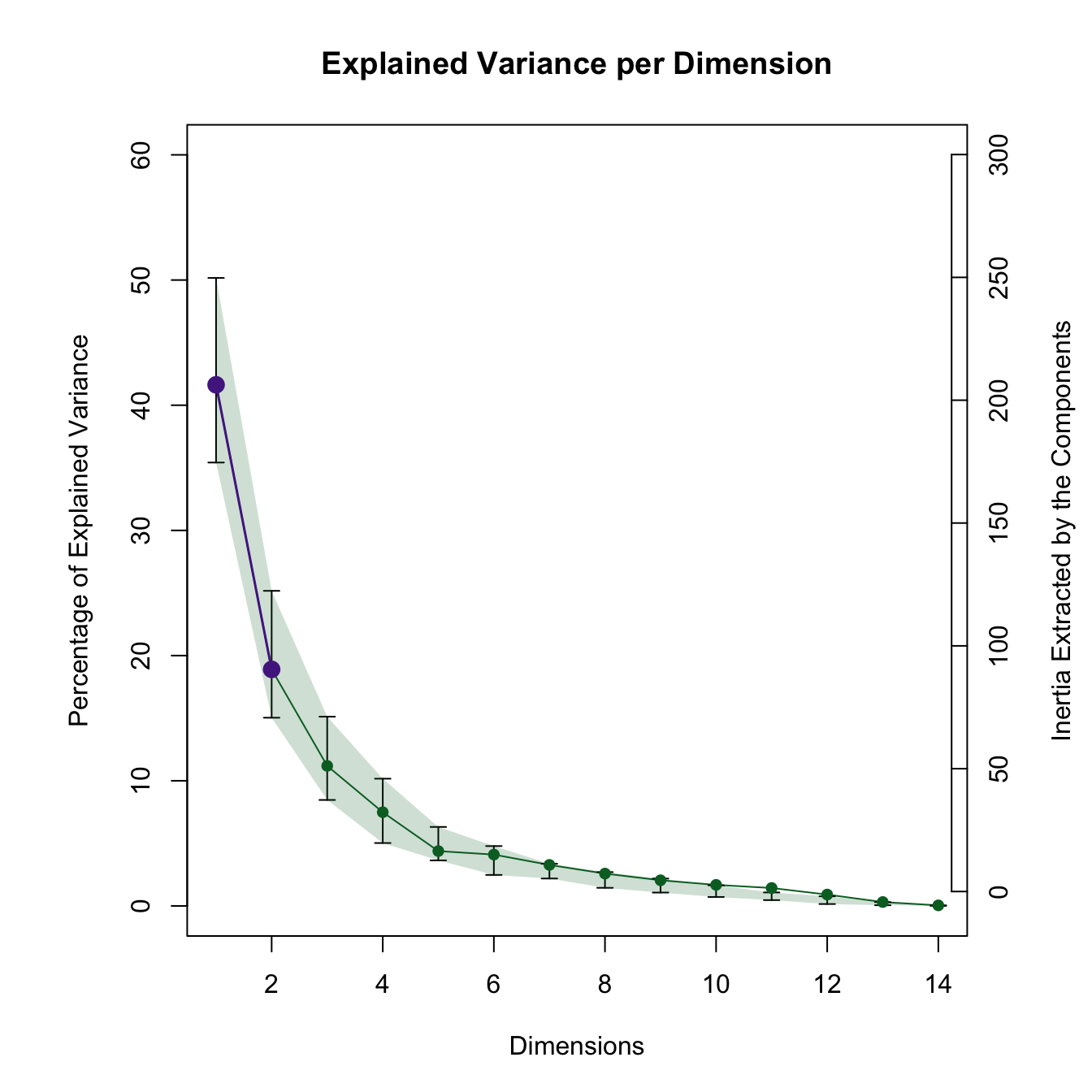
Scree plot
The scree plot shows the eigenvalues of each component. These eigenvalues give the variance of each component (or called dimension in the figure). In other words, the singular values, which are the square root of the eigenvalues, give the standard deviations of these components. The sum of the eigenvalues is equal to the total inertia of the data.
R code
res.plot.pca$results.graphs$scree
According to the elbow test, there are four dimensions to keep for these data.
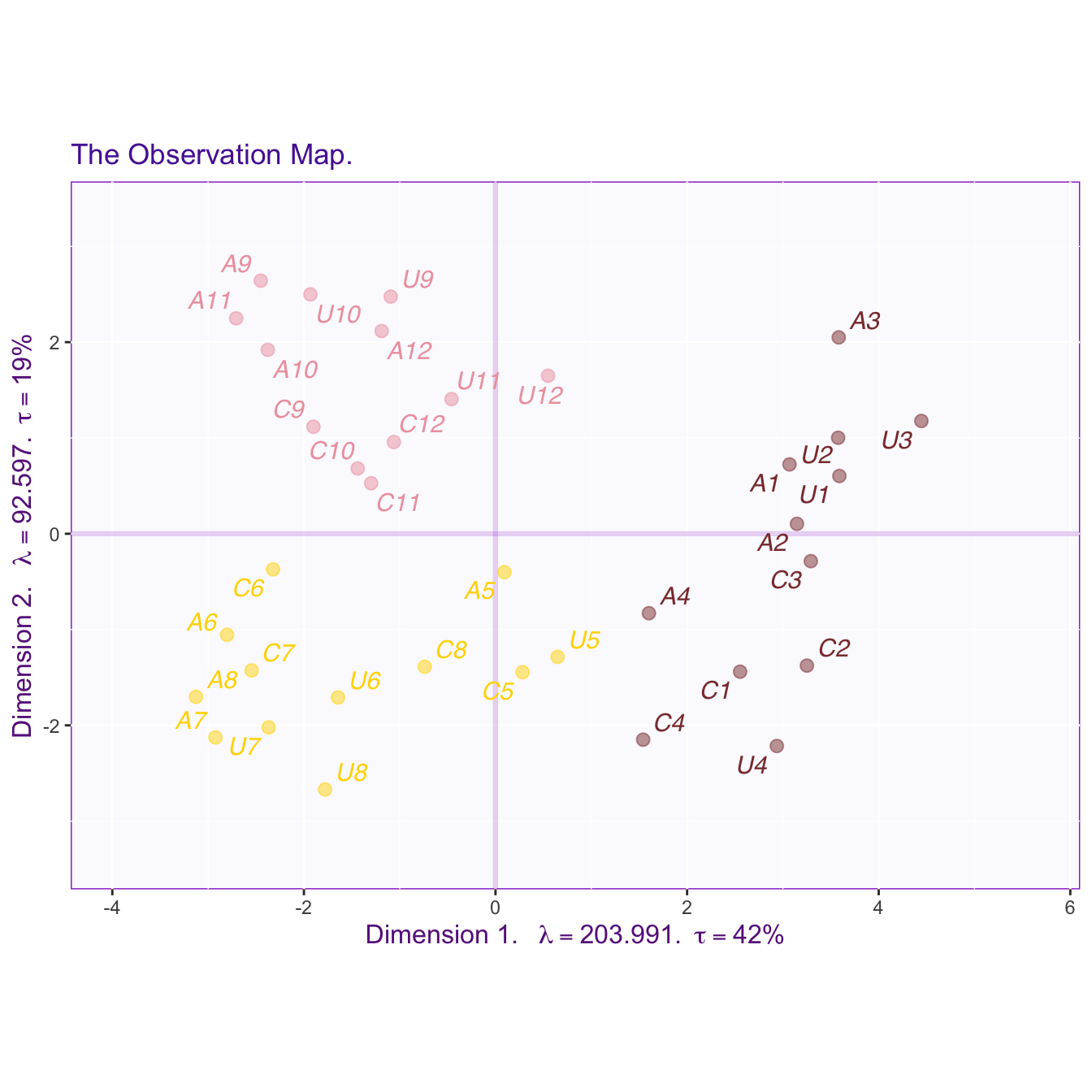
Factor scores (rows)
Here, the observation map shows how the observations (i.e., rows) are represented in the component space. If center = TRUE when running a PCA with epPCA, the origin is at the center (i.e., is the average / barycenter) of all observations. (If it’s not, something’s wrong)
R code
res.plot.pca$results.graphs$factorScoresI12
The wines are colored according to their type (i.e., red, white or rosé in this figures. The result in this plot showed that the first dimension separates all red wines from white and rosé, and the second dimension separates white from rosé.
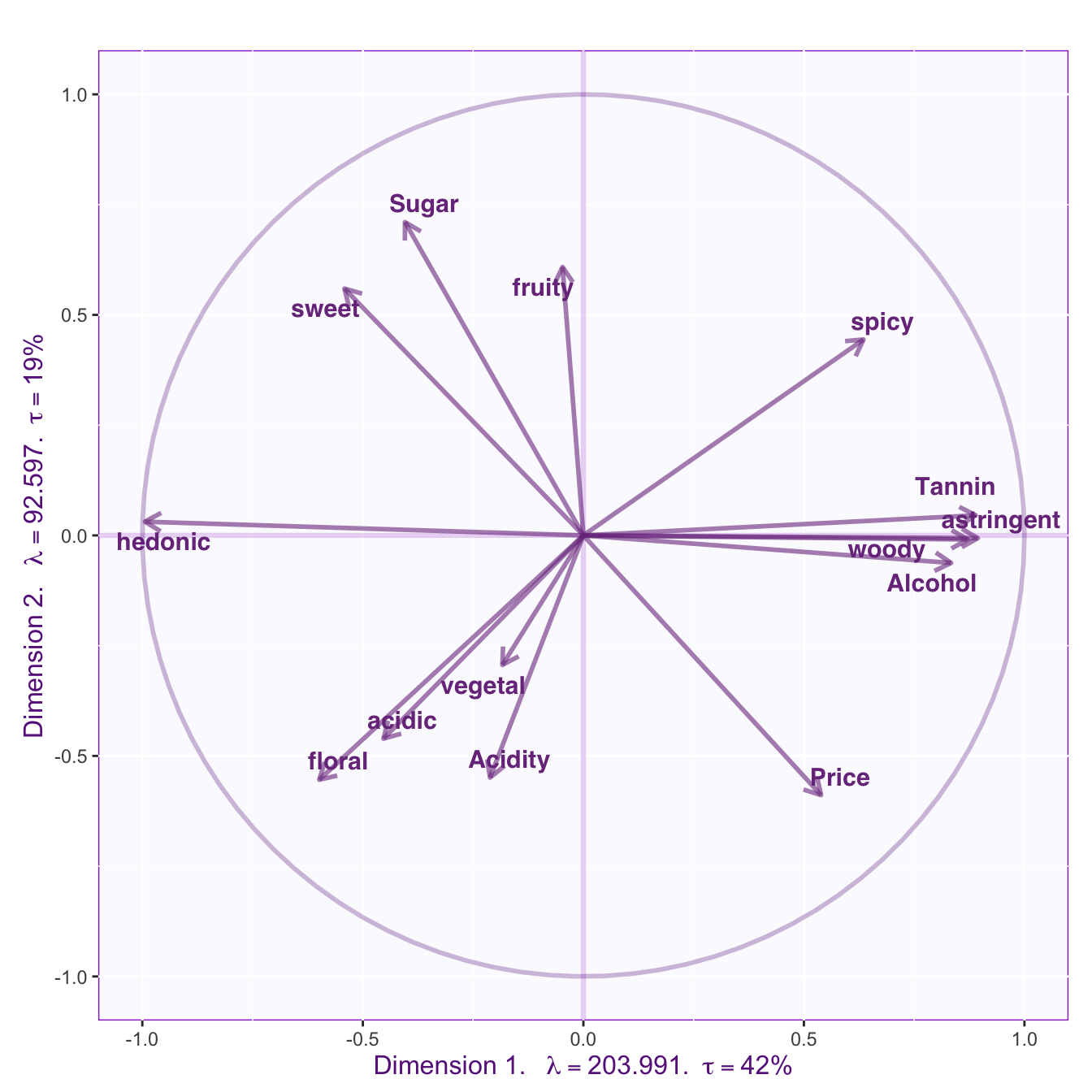
Circle of correlation
The circle of correlations illustrate how the variables are correlated with each other and with the dimensions. From this figure, the length of an arrow indicates how much this variable is explained by the two given dimensions. The cosine between any two arrows gives their correlation. The cosine between a variable and an axis gives the correlation between that variable and the corresponding dimension.
In this figure, an angle closer to 0° indicates a correlation close to 1; an angle closer to 180° indicates a correlation close to -1; and an 90° angle indicates 0 correlation. However, it’s worth noted that this implication of correlation might only be true within the given dimensions. When a variable is far away from the circle, it is not fully explained by the dimensions, and other dimensions might be characterized by other pattern of relationship between this and other variables.
R code
res.plot.pca$results.graphs$cosineCircleArrowJ12
This circle of correlation plot illustrates that Dimension 1 is Tannin, Astringent, Woody, and Alcohol (as well as Price and Spicy) versus Hedonic (as well as Sugar, Sweet, Floral, Acidic, Vegetal, and Acidity); Dimension 2 is Fruity, Spicy, Sugar and Sweet versus Acidity, Floral, Acidic, Price, and Vegetal. Interestingly, Price, as well as the anti-correlated Sweet and Sugar, are orthogonal to Spicy, Acidity, Acidic, Floral, and Vegetal, where Spicy is anti-correlated to the other variables.
Inference plots and results
The inference analysis of PCA (performed by OTAplotInference) includes bootstrap test of the proportion of variance explained, permutation tests of the eigenvalues, the bootstrap tests of the column factor scores \(\mathbf{G}\) (i.e., the right singular vectors scaled to have the variance of each dimension equals the corresponding singular value; \(\mathbf{G} = \mathbf{Q}\boldsymbol{\Delta}\) with \(\mathbf{X = P}\boldsymbol{\Delta}\mathbf{Q}^\top\)). These column factor scores are stored as fj in the output of epPCA.
Bootstrap and permutation tests on the eigenvalues
The inference scree plot illustrates the 95% bootstrap confidence intervals of the percentage of variance explained by each eigenvalue. If an interval includes 0, the component explains reliably larger than 0% of the variance.
R code
res.plot.pca.inference$results.graphs$scree
The bootstrap test identifies one significant dimension explains the variance reliably larger than 0%. The permutation test identifies one significant dimension with an eigenvalue significantly larger than 0.
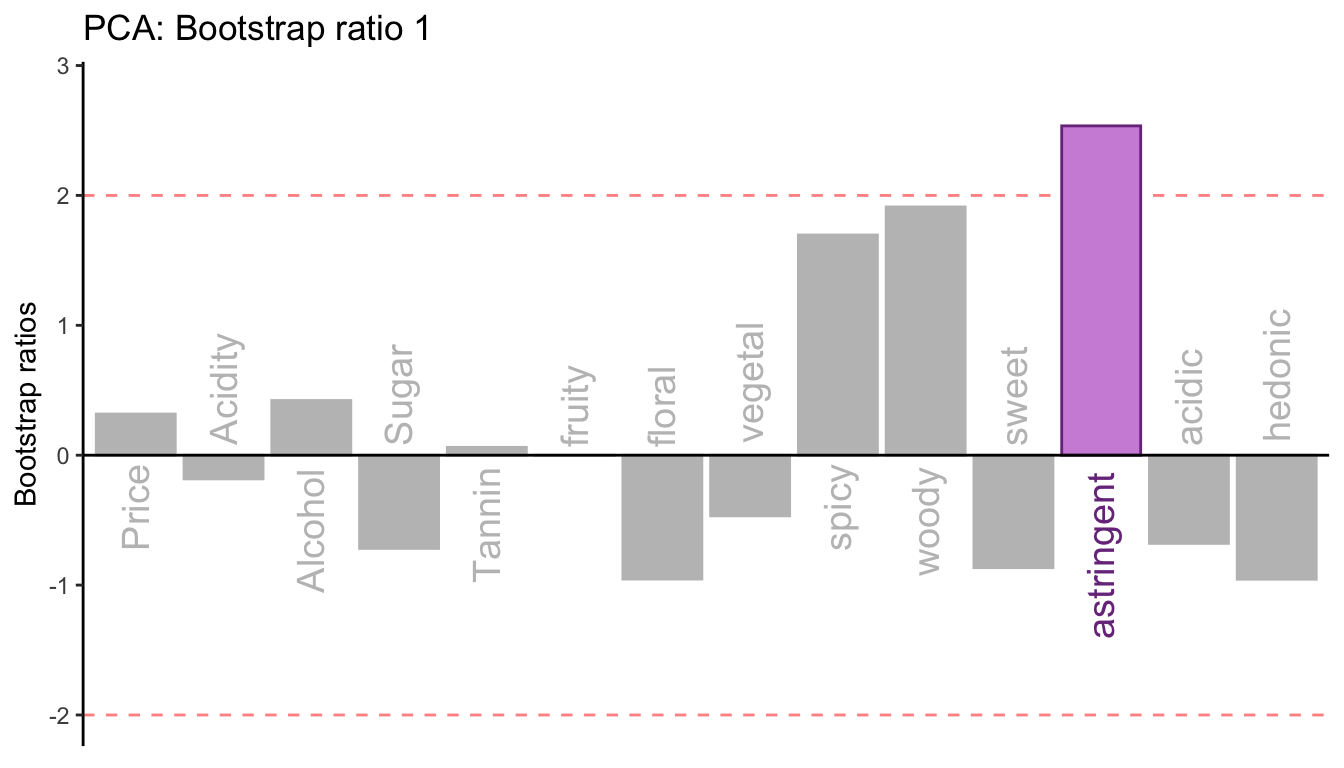
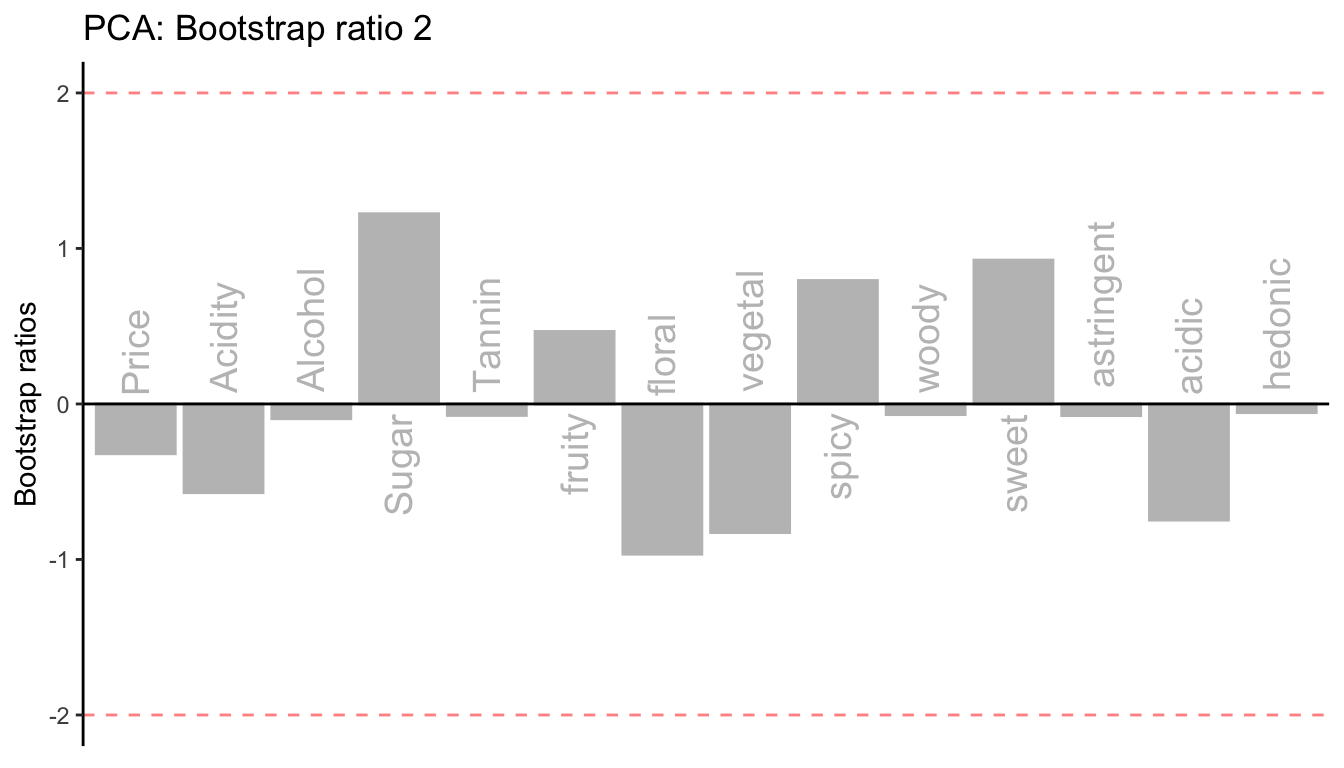
Bootstrap test on the column factor scores
The bar plot illustrates the bootstrap ratios which equals \[\frac{M_{g_{j}boot}}{SD_{g_{j}boot}},\] where \(M_{g_{j}boot}\) is the mean of the bootstrapped sample of the jth column factor score and \(SD_{g_{j}boot}\) is the bootstrapped standard deviation of the factor score. A bootstrap ratio is equivalent to a t-statistics for the column factor score with the \(\mathrm{H}_0: g_j = 0\). The threshold is set to 2 to approximate the critical t-value of 1.96 at \(\alpha\) = .05.
R code
res.plot.pca.inference$results.graphs$BR1
R code
res.plot.pca.inference$results.graphs$BR2
The results show that Astringent is the only significant contributor to Dimension 1, and there is no significant factor scores for Dimension 1 that is reliably different from 0.